Oracle Digital Assistant and GPT For Document & Site Search..


Recently I've been putting some time into investigating GPT capabilities and pulling together a few concepts with what is possible and could be achieved with Oracle Cloud platforms like Oracle Digital Assistant.
With ODA already in place as a chat interface - I thought it would be great to extend it and create a new skill that allows it to interact with GPT and information that I've ingested from a suite of public documents and all the content from the Fishbowl Solutions website.
Examples below..
What is ODA?
Oracle Digital Assistant is a powerful cloud solution that enables you to create chatbots that can be designed to connect and interact with multiple sources using skills via natural language conversations to help you more easily accomplish tasks.
For example you could create a skill to order a Pizza or make reservations for a hotel using Web, Voice or Text Messaging through natural language that would then interact with services to help complete a desired task from a conversation flow.
Why use GPT and not build your own flow?
There is nothing stopping you from building your own targeted skills - check out Oracles Artie Bot that helps you learn about Digital Assistants' and it's capabilities with it's own personality and more.
On top of this you can more easily control, extend and enhance the conversation flow and add interactive elements to help assist and guide the user to information they are looking for via an interactive admin UI on the cloud.
With GPT-3 you could build in prompts to help with the conversational flow but from my initial experimentation ODA today does a better job for streamlining the conversation flow and an easy to manage admin conversation interface - however with that said using GPT is far easier and faster to spin up and has the ability to ingest a website and documentation within minutes that can be queried via a conversation rather than programmed via intents.
With GPT-4 it won't be just language text based interactions but more capabilities such as the ability to upload assets, create interactive elements, buttons drops, displaying and extracting images to be displayed in the conversation and with recent announcement yesterday the ability to build GPT-4 Plugins..
Enhancements
One of the things I haven't been able to do at this stage is return a link to the original documentation that I've ingested - so as part of the ODA skill phase2 - I'm going to tie it into Elastic or MindBreeze search to return a list of 5 relevant docs the user can download from. (Maybe with GPT4 this will be easier?)
Lets take a quick look
What I've done is ingested the Fishbowl Website - essentially exported all the data as an XML file and then converted the XML to MD page assets - which I've used to create a Faiss (Vector DB) library from that enables efficient similarity search.
Here are the some of results..
Lets start off with something simple..
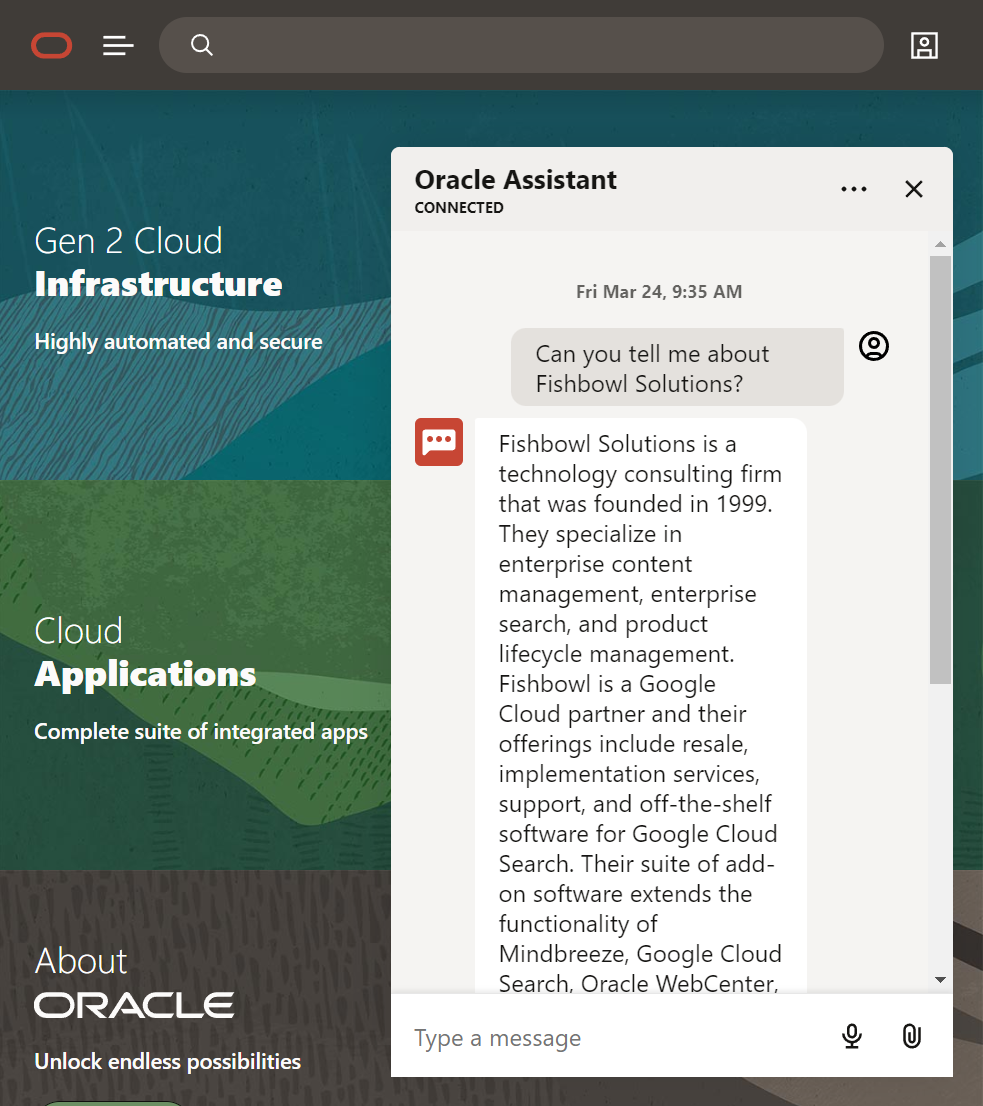
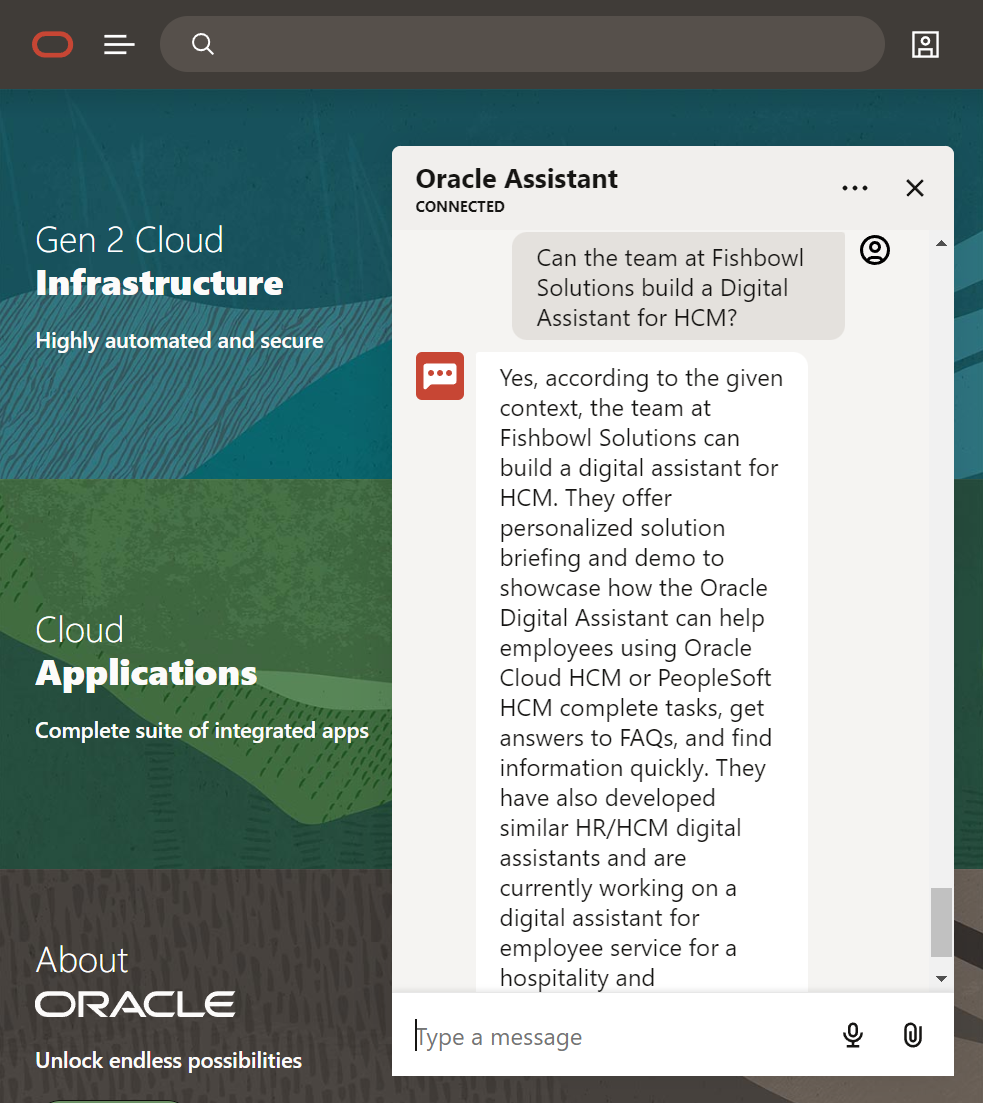
GPT hasn't taken an extract of a paragraph of content from the site - but has extracted elements which it believes are relevant to recreate a response from the data that is available - it is pretty spot on although some of the site content may need updating.
If we feel the results are incorrect - we can report back to Open AI and help fine tune the data returned or enhance the prompting capabilities.
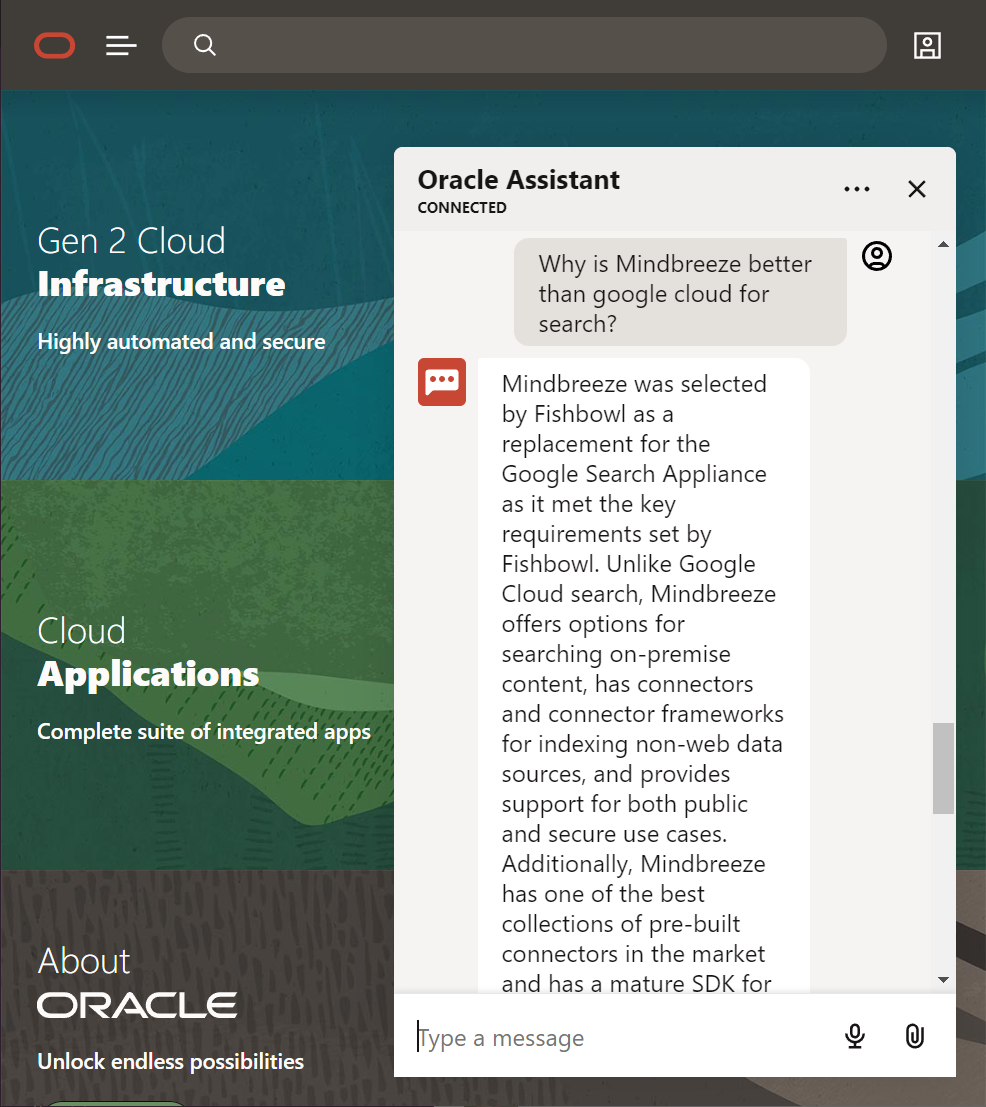
By magic GPT has been able to extract the relevant info and formulate a response.
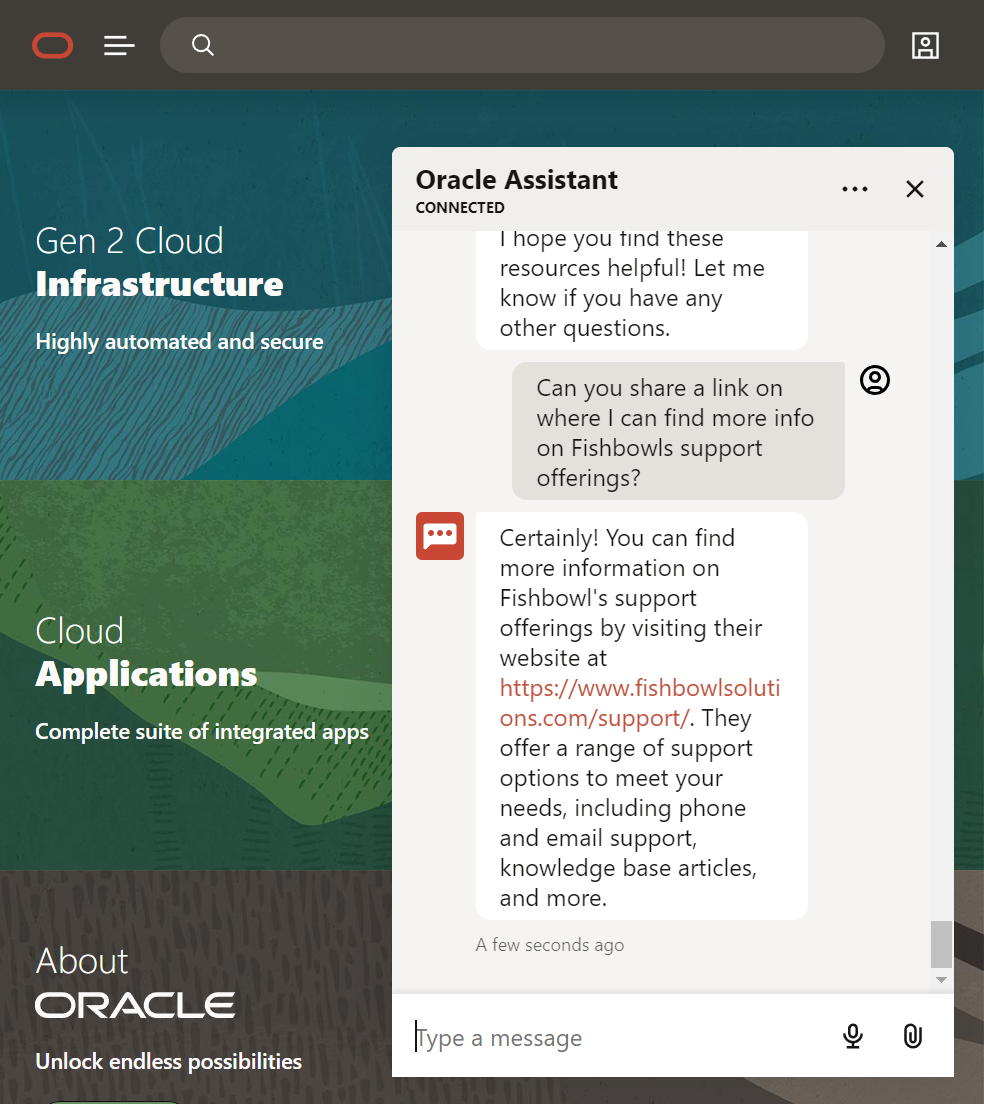
Links can also be provided as part of the response as long as those links have been ingested and are contained as part of the document. - if they are not in the document even if you crawl a site - GPT won't know the URL to respond with.
And finally a quick example of Document Ingestion
As I'm running GPT-3 images aren't extracted and returned - but that is coming.
- I loved the fact that it enhanced the response to provide me guided steps.
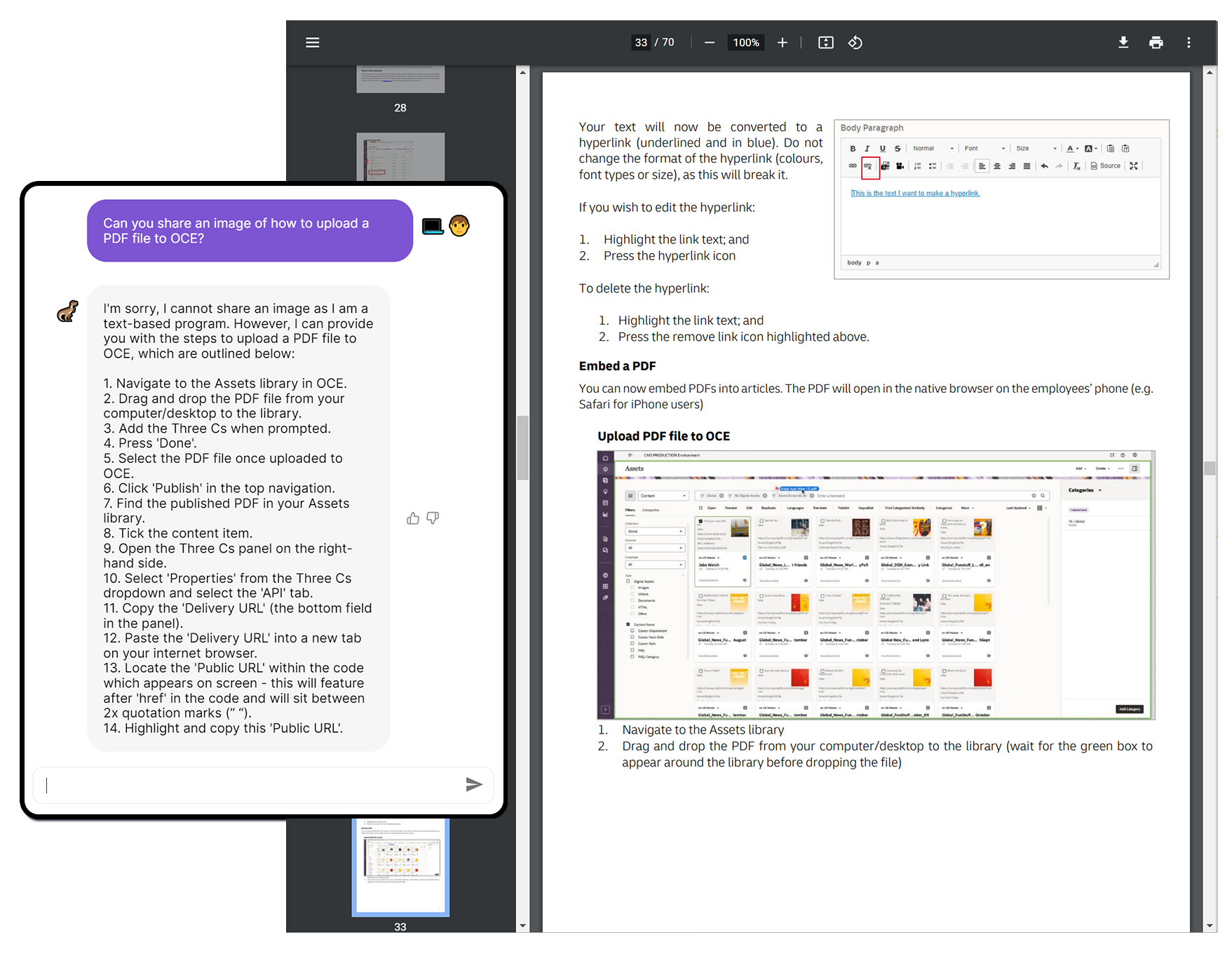
I was also able to do things such as the following query:
"How many content types are there in this project?"
And GPT was able to recognize what an asset type was as well as list and count them from within the document.
"Based on the different pieces of context provided, the most common answer is that this project has five content types, which are articles, videos, galleries, external links, and FAQs"
There was no number stating 5 and just a high level paragraph on what content types were within the document.
Final Words..
Digital Assistants are changing fast and I'm just scratching at the surface at the moment of what can be achieved with them and the power of combining GPT with an integrated service layer to help quickly complete tasks and retrieve relevant information.
It's an exciting time to see what others are building like JPMorgan, Stripe: